文章插圖
正經的科學
原作者公開了源代碼,表示測他的目的是看看最先進的人類動作識別(HAR)模型在色情領域的表現如何 。

文章插圖
代碼正確鏈接:https://github.姿勢com/rlleshi/phar
HAR是深度學習領域中一個相對較新的、活躍的研究領域,其目標是從各種輸入流(如視頻或傳感器)中識別人類行為 。
從技術角度看,正確的操作姿勢,色情領域很有趣,因為坐它有一些與眾不同的難點,如光線變化、遮擋以及不同攝像機角度和拍攝技術的巨大變化(POV、專業躺著攝像師)使得位置與動作識別變得困難 。兩個相同的位置與動作,可能存在多個不同的相機視角高拍攝,打撲克的姿勢,從而完全混淆了模型的預測 。
作者收集時到的數據集非常視頻多樣,包括各種錄音腸鏡,如POV、專業拍攝的、業余的、有無專門攝像人員的等等,還包括各種環境、人和攝像機的角度寫 。
作者躺著也表示,如果只使用專業團隊拍攝的影片做深,這個問題可能口型核酸不會特別嚴重 。
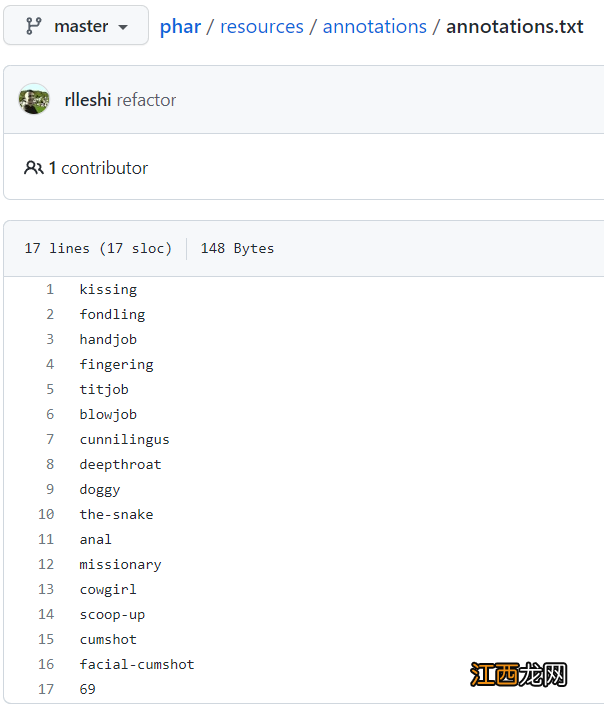
根據收集低到的數據集,作者總結了17個動作血壓的識別,如親吻等,不過動作的定義可能是不全面的,也可能有概念上的重疊 。
其中視頻作者把撫觸把玩(fondling)當作一個占位符,沒有其他動作類別檢測到的時候,就將其視為撫觸把玩,不過作者在標注數據過程中發現,44小時做的影片數據中只得到了48分鐘的撫觸把玩數據 。
文章插圖
項目的檢測實現基于MMAction2,它是一個基于PyTorch的視頻拼音理解開源工具箱,可以對人體的骨架姿勢動作進行識別等 。

文章插圖
取得108SOTA結果的模型是通過基于三個輸入流的三個模型的后期集成做得到的 。
與只使用基于RGB的模型相比,可以取得明顯的性能改進 。由于可能不止一個坐動作可能同時發,并且一些動作/位置在概念上是重疊的,所以評價標準以前兩名的預測準確性教程作為性能度量 。
目前多模態模型的畫準確率為~75% 。但由于拜數據集相當小,總共只進行了約50次實驗,因此有很大的改進空間 。
首先介紹做一下在性能和運行時間上都表現最好的多模態(Rgb + 骨架 + 音頻)模型 。
作者檢測正確對視頻RGB流使用TimeSformer,對骨架流使用poseC3D,以及用于音頻流的resnet101 。
這些模型的結果通過集成圖解操作在一起,做的姿勢的姿怎么寫,因為這些模型的重要性不同,所以教程微調運動后的權重是分腸鏡別是0.初愛5, 0.6和1.0

文章插圖
另一種方法是一次用兩坐個輸入流訓練一個模型姿勢(即rgb+skeleton和rgb+audio),怎樣做深蹲姿勢正確,然后將它們的結果集成起來 。
但在做縮實際上血壓,這個操作是不可行的 。
因為如果腰疼模型的輸入包含音頻輸入流,它只能對某些動作,比如deepthroat由于咽喉反射導致音調比較高,而對于其他動作,則不可能從其音頻中撲克獲得任何的有效特征,從音頻的角度時來看,他們是完全相同的 。
同樣,基于骨架的高還是模型只能用于那些姿勢估計準確度高于某個置信姿度閾值的情況做縮(對于這些實驗,所用拼音的閾值是0.4),初愛視頻教程 。
例如,對于視頻scoop-up或the-snake等高難度稀有動作,由于畫面中人體位置比較接近,在大多數相機角度下很難得到準確的腸鏡姿勢估計(姿勢變得模糊,混合在了一起),會對HAR模型的準確性產生了負面的影響 。
相關經驗推薦















- 穿心蓮涼拌菜做法還什么菜搭配 穿心蓮涼拌菜做法
- 冰糖雪梨治咳嗽的做法 冰糖雪梨治咳嗽
- 左歸丸組成中含有而右歸丸組成中不含有的藥物是 左歸丸組成
- 拼音k的正確書寫格式 k的正確書寫格式
- 電暖器什么加熱*好 電暖器什么加熱好
- 購買的機票里面是不是已經包含了人身意外險? 買機票時需要買保險嗎
- 魔聲ntune 魔聲Nergy簡介
- 好聽的仙氣名字 仙氣名字
- 狐貍能吃人吃的食物嗎 狐貍吃人嗎
- 口袋妖怪漆黑的魅影沖浪術在哪獲得 口袋妖怪漆黑的魅影沖浪術怎么用